|
|
|
@@ -0,0 +1,314 @@ |
|
|
|
Données binaires |
|
|
|
================ |
|
|
|
|
|
|
|
Introduction : chiffres et nombres |
|
|
|
----------------------------------- |
|
|
|
|
|
|
|
Si je vous parle de ce que représente le texte: ``342`` vous pouvez le |
|
|
|
voir de deux façons: |
|
|
|
|
|
|
|
1. C'est une **suite de chiffres**: ``3``, puis ``4``, puis ``2``. |
|
|
|
1. C'est un **nombre** (quelque part entre 300 et 350) |
|
|
|
|
|
|
|
On se sert des *chiffres* de 0 à 9 pour *représenter* des *nombres* |
|
|
|
|
|
|
|
La base 10 |
|
|
|
---------- |
|
|
|
|
|
|
|
Plus exactement, pour passer de la suite de chiffres ``342`` au nombre, |
|
|
|
on part de la fin, puis on ajoute chaque chiffre, multiplié par la puissance |
|
|
|
de 10 adéquate:: |
|
|
|
|
|
|
|
2 * 1 |
|
|
|
+ 4 * 10 |
|
|
|
+ 2 * 10 * 10 |
|
|
|
|
|
|
|
soit:: |
|
|
|
|
|
|
|
2 |
|
|
|
+ 40 |
|
|
|
+ 300 |
|
|
|
|
|
|
|
ce qui fait bien 342. |
|
|
|
|
|
|
|
|
|
|
|
La base 16 |
|
|
|
---------- |
|
|
|
|
|
|
|
En informatique, on se sert souvent de la base 16. C'est le même principe: on se |
|
|
|
sert des "chiffres" de 0 à F (A vaut 10, B vaut 11, jusqu'à F qui vaut 15) |
|
|
|
|
|
|
|
Ainsi, la suite ``DA2`` peut être interprétée comme suit :: |
|
|
|
|
|
|
|
2 * 1 |
|
|
|
+ 10 * 16 |
|
|
|
+ 13 * 16 * 16 |
|
|
|
|
|
|
|
soit :: |
|
|
|
|
|
|
|
2 |
|
|
|
+ 160 |
|
|
|
+ 3328 |
|
|
|
|
|
|
|
soit 3746 |
|
|
|
|
|
|
|
On appelle aussi la base 16 la base *hexadécimale*, ou *hexa* en abrrégé. |
|
|
|
|
|
|
|
La base 2 |
|
|
|
---------- |
|
|
|
|
|
|
|
La base 2 c'est pareil, mais avec deux "chiffres" - 0 et 1. |
|
|
|
|
|
|
|
Ainsi, la suite `110` peut être interprétée comme suit :: |
|
|
|
|
|
|
|
0 * 1 |
|
|
|
+ 1 * 2 |
|
|
|
+ 1 * 2 * 2 |
|
|
|
|
|
|
|
soit :: |
|
|
|
|
|
|
|
0 |
|
|
|
+ 2 |
|
|
|
+ 4 |
|
|
|
|
|
|
|
soit 6. |
|
|
|
|
|
|
|
|
|
|
|
Bits et octets |
|
|
|
-------------- |
|
|
|
|
|
|
|
* Un bit (*bit* en anglais) c'est la valeur 1 ou 0 |
|
|
|
* Un octet (*byte* en anglais) c'est une suite de 8 bits |
|
|
|
|
|
|
|
À retenir |
|
|
|
--------- |
|
|
|
|
|
|
|
**Ces paquets de 8 ne veulent rien dire en eux-mêmes**. |
|
|
|
Ils n'ont de sens que dans le cadre d'une *convention*. |
|
|
|
|
|
|
|
Par exemple, l'octet '10100100' peut être un nombre écrit en |
|
|
|
binaire (164 en l'occurrence), mais peut avoir une toute |
|
|
|
autre signification |
|
|
|
|
|
|
|
Le nombre de valeurs possible augmente *très* rapidement avec le nombre d'octets: |
|
|
|
|
|
|
|
* 1 octet, c'est 255 valeurs possibles (``2 ** 8``) |
|
|
|
* 2 octets, c'est 65.536 valeurs possibles (``2 ** 16``) |
|
|
|
* 4 octets, c'est 4.294.967.296 valeurs possibles (``2 ** 32``) |
|
|
|
|
|
|
|
Bases en Python |
|
|
|
--------------- |
|
|
|
|
|
|
|
On se sert des préfixes `0b` et `0x` pour noter |
|
|
|
les nombres en base binaire ou hexadécimale respectivement:: |
|
|
|
|
|
|
|
print(0b1110) |
|
|
|
# affiche: 6 |
|
|
|
|
|
|
|
print(0xDA2) |
|
|
|
# affiche: 3490 |
|
|
|
|
|
|
|
Poids des bits |
|
|
|
-------------- |
|
|
|
|
|
|
|
Regardez l'example suivant:: |
|
|
|
|
|
|
|
x = 0b0010010 # 18 |
|
|
|
y = 0b0010011 # 19 |
|
|
|
z = 0b1010010 # 82 |
|
|
|
|
|
|
|
Notez que le premier bit est plus "fort" que le dernier on dit qu'on est en "little endian". |
|
|
|
|
|
|
|
|
|
|
|
Manipuler des octets en Python |
|
|
|
------------------------------ |
|
|
|
|
|
|
|
On peut construrie des listes d'octets en utilsant ``bytearray`` et |
|
|
|
une liste de nombres:: |
|
|
|
|
|
|
|
data = bytearray( |
|
|
|
[0b1100001, |
|
|
|
0b1100010, |
|
|
|
0b1100011 |
|
|
|
] |
|
|
|
) |
|
|
|
|
|
|
|
# equivalent: |
|
|
|
data = bytearray([97,98,99]) |
|
|
|
|
|
|
|
# equivalent aussi: |
|
|
|
data = bytearray([0x61, 0x62, 0x63] |
|
|
|
|
|
|
|
|
|
|
|
Texte |
|
|
|
----- |
|
|
|
|
|
|
|
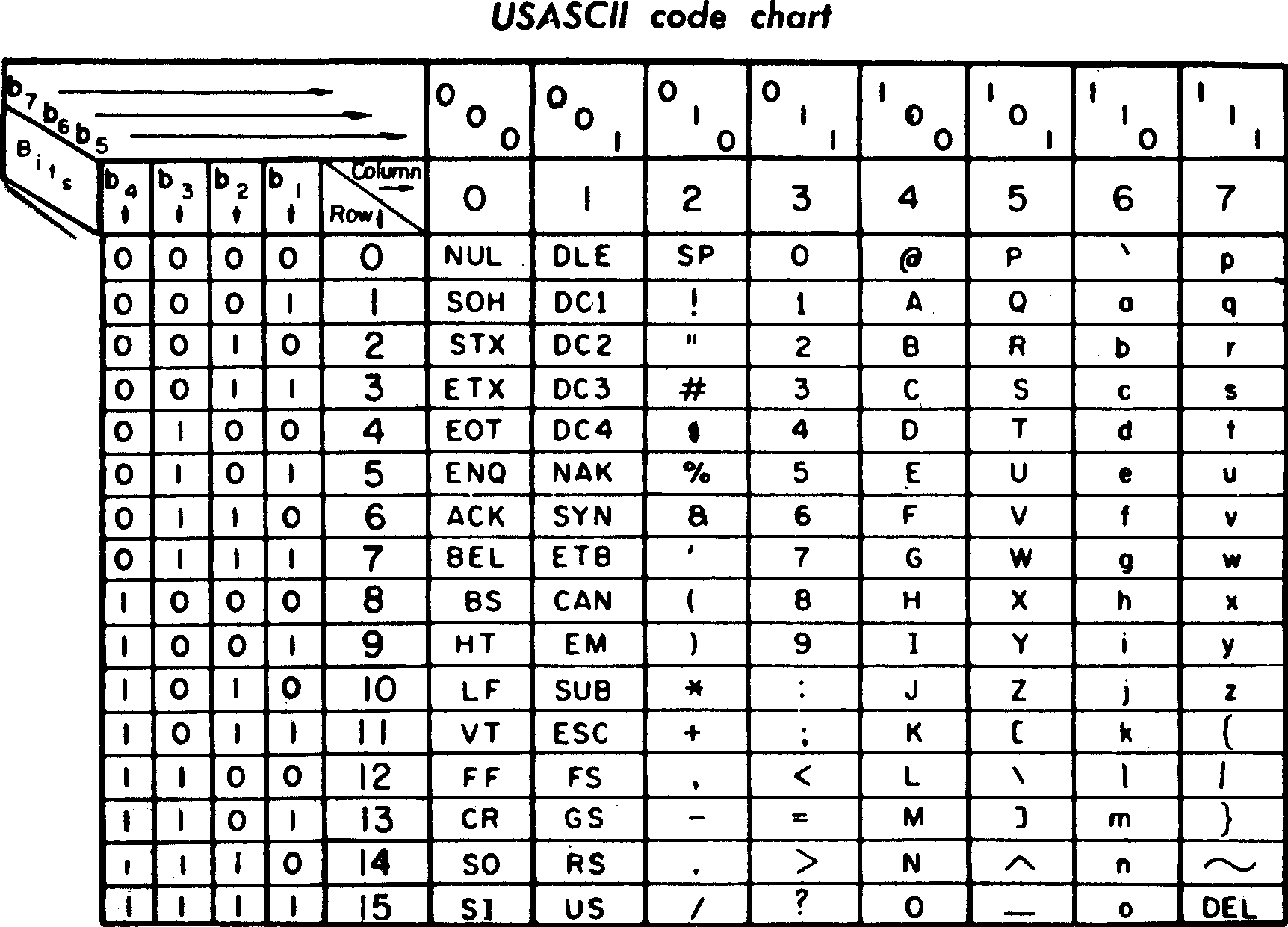
On peut aussi interpréter des octets comme du texte - c'est la table ASCII |
|
|
|
|
|
|
|
.. image:: ../img/ascii-table.png |
|
|
|
|
|
|
|
|
|
|
|
ASCII - remarques |
|
|
|
----------------- |
|
|
|
|
|
|
|
* C'est *vieux* - 1960 |
|
|
|
* Le A est pour American |
|
|
|
* Ça sert à *envoyer* du texte sur des terminaux d'où les "caractères" non-imprimables dans la liste |
|
|
|
* Mais c'est une convention *très* utilisée |
|
|
|
* Techniquement, on n'a besoin que de 7 bits, mais on préfère envoyer des octets |
|
|
|
|
|
|
|
Utiliser ASCII en Python |
|
|
|
------------------------ |
|
|
|
|
|
|
|
Avec ``chr`` et ``ord``:: |
|
|
|
|
|
|
|
x = chr(98) |
|
|
|
print(x) |
|
|
|
# affiche: b |
|
|
|
|
|
|
|
x = ord('a') |
|
|
|
print(x) |
|
|
|
# affiche: 97 |
|
|
|
|
|
|
|
Affichage des bytearrays en Python |
|
|
|
---------------------------------- |
|
|
|
|
|
|
|
Python utilise ASCII pour afficher les bytearrays si les caractères sont "imprimables":: |
|
|
|
|
|
|
|
data = bytearray([97,98,99]) |
|
|
|
print(data) |
|
|
|
# affiche: bytearray(b"abc") |
|
|
|
|
|
|
|
Et ``\x`` et le code hexa sinon:: |
|
|
|
|
|
|
|
data = bytearray([7, 69, 76, 70]) |
|
|
|
print(data) |
|
|
|
# affiche: bytearray(b"\x07ELF") |
|
|
|
|
|
|
|
Notez bien que ce qu'affiche Python n'est qu'une *interpétation* d'une séquence d'octets. |
|
|
|
|
|
|
|
Types |
|
|
|
----- |
|
|
|
|
|
|
|
La variable `b"abc"` est une "chaîne d'octets", de même que `"abc"` est une "chaîne de caractères". |
|
|
|
|
|
|
|
Python apelle ces types `bytes` et `str`:: |
|
|
|
|
|
|
|
print(type("abc")) |
|
|
|
# affiche: str |
|
|
|
|
|
|
|
print(type(b"abc")) |
|
|
|
# affiche: bytes |
|
|
|
|
|
|
|
|
|
|
|
bytes et bytearray |
|
|
|
------------------ |
|
|
|
|
|
|
|
De la même manière qu'on ne peut pas modifier un caractère à l'intérieur une string, on ne peut |
|
|
|
pas modifier un bit - ou un octet dans une variable de type `bytes`:: |
|
|
|
|
|
|
|
a = "foo" |
|
|
|
# a[0] = "f" => TypeError: 'str' object does not support item assignment |
|
|
|
|
|
|
|
b = b"foo" |
|
|
|
# b[0] = 1 => TypeError: 'bytes' object does not support item assignment |
|
|
|
|
|
|
|
Par contre on peut modifier un bytearray:: |
|
|
|
|
|
|
|
b = bytearray(b"foo") |
|
|
|
b[0] = 103 |
|
|
|
print(b) |
|
|
|
# affiche: bytearray(b"goo") |
|
|
|
|
|
|
|
Conversion bytes - texte |
|
|
|
------------------------ |
|
|
|
|
|
|
|
Avec ``encode()`` et ``decode()``:: |
|
|
|
|
|
|
|
text = "chaise" |
|
|
|
encodé = text.encode("ascii") |
|
|
|
print(encodé) |
|
|
|
# affiche: b"chaise" |
|
|
|
|
|
|
|
bytes = b"table" |
|
|
|
décodé = bytes.decode("ascii") |
|
|
|
print(décodé) |
|
|
|
# affiche: b"table" |
|
|
|
|
|
|
|
|
|
|
|
Notez que dans le deuxième exemple, on est bien en train de "décoder" |
|
|
|
un paquet de 0 et de 1. Il peut s'écrire ainsi: |
|
|
|
|
|
|
|
|
|
|
|
bytes = b"\x74\x61\x62\x6c\x65" |
|
|
|
décodé = bytes.decode("ascii") |
|
|
|
print(décodé) |
|
|
|
# affiche: table |
|
|
|
|
|
|
|
Plus loin que l'ASCII |
|
|
|
--------------------- |
|
|
|
|
|
|
|
Vous avez sûrement remarquer qu'il n'y a pas de caractères accentués dans |
|
|
|
ASCII. Du coup, il existe d'autres *conventions* qu'on appelle "encodage". |
|
|
|
|
|
|
|
On peut spécifier l'encodage quand on appelle la méthode ``decode()``:: |
|
|
|
|
|
|
|
# latin-1: utilisé sur certains vieux sites |
|
|
|
data = bytearray([233]) |
|
|
|
lettre = data.decode('latin-1') |
|
|
|
print(lettre) |
|
|
|
# affiche: 'é' |
|
|
|
|
|
|
|
# cp850: dans l'invite de commande Windows |
|
|
|
data = bytearray([233]) |
|
|
|
lettre = data.decode('cp850') |
|
|
|
print(lettre) |
|
|
|
# affiche: 'Ú' |
|
|
|
|
|
|
|
Notez que la même suite d'octets a donné des résultats différents en fonction |
|
|
|
de l'encodage! |
|
|
|
|
|
|
|
Unicode |
|
|
|
-------- |
|
|
|
|
|
|
|
L'Unicode c'est deux choses: |
|
|
|
|
|
|
|
1. Une **table** qui associe un un "codepoint" à chaque caractère |
|
|
|
2. Un encodage particulier, l'UTF-8, qui permet de convertir une suite |
|
|
|
d'octets en suite de codepoint et donc de caractères |
|
|
|
|
|
|
|
UTF-8 en pratique |
|
|
|
------------------ |
|
|
|
|
|
|
|
D'abord, UTF-8 est compatible avec ASCII:: |
|
|
|
|
|
|
|
encodé = "abc".encode("utf-8") |
|
|
|
print(encodé) |
|
|
|
# Affiche: b'abc' |
|
|
|
|
|
|
|
Ensuite, certains caractères (comme ``é``) sont représentés par 2 octets:: |
|
|
|
|
|
|
|
encodé = "café".encode("utf-8") |
|
|
|
print(encodé) |
|
|
|
# Affiche: b'caf\xc3\xa9" |
|
|
|
|
|
|
|
|
|
|
|
Enfin, certains caractères (comme les emojis) sont représentés par pleins d'octets:: |
|
|
|
|
|
|
|
encodé = "I ❤️ you".encode("utf-8") |
|
|
|
print(encodé) |
|
|
|
b'I \xe2\x9d\xa4\xef\xb8\x8f you' |
|
|
|
|
|
|
|
|
|
|
|
.. warning:: |
|
|
|
|
|
|
|
Toutes les séquences d'octets ne sont pas forcément valides quand on veut |
|
|
|
les décoder en UTF-8 |
|
|
|
|
|
|
|
Conséquences |
|
|
|
------------- |
|
|
|
|
|
|
|
* On peut représenter *tout* type de texte avec UTF-8 (latin, chinois, coréen, langues disparues, ....) |
|
|
|
* On ne peut pas accéder à la n-ème lettre directement dans une chaîne |
|
|
|
encodée en UTF-8, il faut parcourir lettre par lettre (ce qui en pratique est rarement |
|
|
|
un problème). |

 Dimitri Merejkowsky
6 年之前
Dimitri Merejkowsky
6 年之前
{kind=link}